C++ 内存管理 —— 如何定位内存泄漏(valgrind)
本文共 4978 字,大约阅读时间需要 16 分钟。
定位内存泄漏(valgrind)
定位内存泄漏(valgrind)
1.1、基本概念
Valgrind是一个GPL的软件,用于Linux(For x86, amd64 and ppc32)程序的内存调试和代码剖析。你可以在它的环境中运行你的程序来监视内存的使用情况,比如C 语言中的malloc和free或者 C++中的new和 delete。使用Valgrind的工具包,你可以自动的检测许多内存管理和线程的bug,避免花费太多的时间在bug寻找上,使得你的程序更加稳固。
安装Valgrind
//valgrind下载:http://valgrind.org/downloads/valgrind-3.12.0.tar.bz2valgrind安装:1. tar -jxvf valgrind-3.12.0.tar.bz22. cd valgrind-3.12.03. ./configure4. make5. sudo make install
- 应用环境:Linux
- 编程语言:C/C++
- 使用方法: 编译时加上
-g选项,如gcc -g filename.c -o filename,使用如下命令检测内存使用情况:
最常用的命令格式:valgrind --tool=memcheck --leak-check=full ./testvalgrind --tool=memcheck --leak-check=full --show-reachable=yes --trace-children=yes ./filename其中--leak-check=full指的是完全检查内存泄漏,--show-reachable=yes是显示内存泄漏的地点,--trace-children=yes是跟入子进程。
如果您的程序是会正常退出的程序,那么当程序退出的时候valgrind自然会输出内存泄漏的信息。如果您的程序是个守护进程,那么也不要紧,我们 只要在别的终端下杀死memcheck进程(因为valgrind默认使用memcheck工具,就是默认参数--tools=memcheck)
- 参数选择
-tool=最常用的选项。运行 valgrind中名为toolname的工具。默认memcheck。 memcheck ------> 这是valgrind应用最广泛的工具,一个重量级的内存检查器,能够发现开发中绝大多数内存错误使用情况,比如:使用未初始化的内存,使用已经释放了的内存,内存访问越界等。 callgrind ------> 它主要用来检查程序中函数调用过程中出现的问题。 cachegrind ------> 它主要用来检查程序中缓存使用出现的问题。 helgrind ------> 它主要用来检查多线程程序中出现的竞争问题。 massif ------> 它主要用来检查程序中堆栈使用中出现的问题。 extension ------> 可以利用core提供的功能,自己编写特定的内存调试工具 -h –help 显示帮助信息。 -version 显示valgrind内核的版本,每个工具都有各自的版本。 -q –quiet 安静地运行,只打印错误信息。 -v –verbose 更详细的信息, 增加错误数统计。 -trace-children=no|yes 跟踪子线程? [default: no] -track-fds=no|yes 跟踪打开的文件描述?[default: no] -time-stamp=no|yes 增加时间戳到LOG信息? [default: no] -log-fd= 输出LOG到描述符文件 [2=stderr] -log-file= 将输出的信息写入到filename.PID的文件里,PID是运行程序的进行ID -log-file-exactly= 输出LOG信息到 file -log-file-qualifier= 取得环境变量的值来做为输出信息的文件名。 [none] -log-socket=ipaddr:port 输出LOG到socket ,ipaddr:portLOG信息输出 -xml=yes 将信息以xml格式输出,只有memcheck可用 -num-callers= show callers in stack traces [12] -error-limit=no|yes 如果太多错误,则停止显示新错误? [yes] -error-exitcode= 如果发现错误则返回错误代码 [0=disable] -db-attach=no|yes 当出现错误,valgrind会自动启动调试器gdb。[no] -db-command= 启动调试器的命令行选项[gdb -nw %f %p]
- 设计思路:根据软件的内存操作维护一个有效地址空间表和无效地址空间表(进程的地址空间)
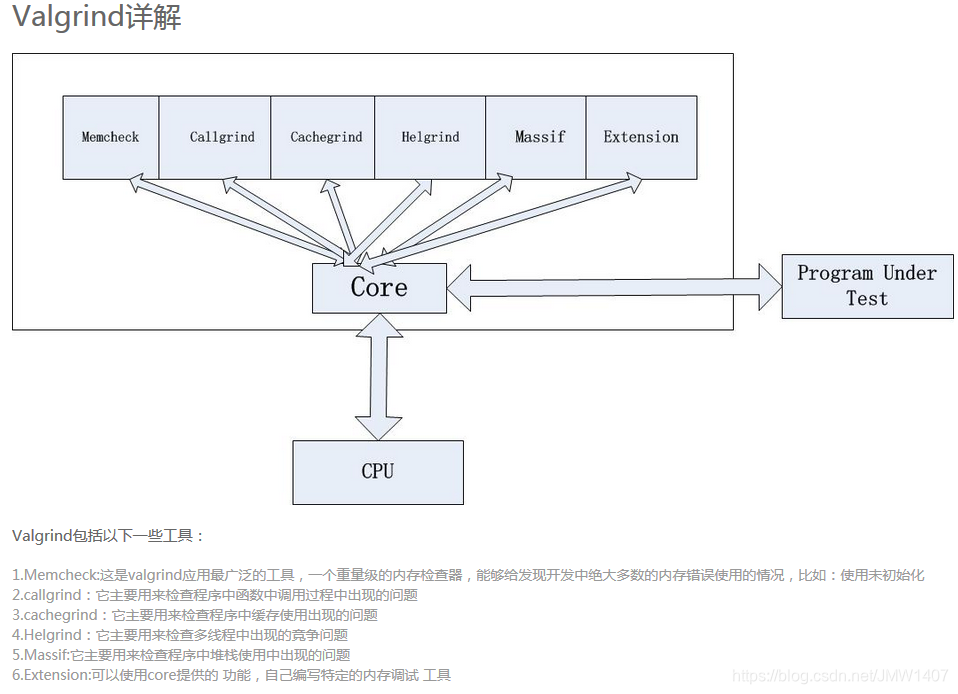
1.2、多个工具
1、Memcheck
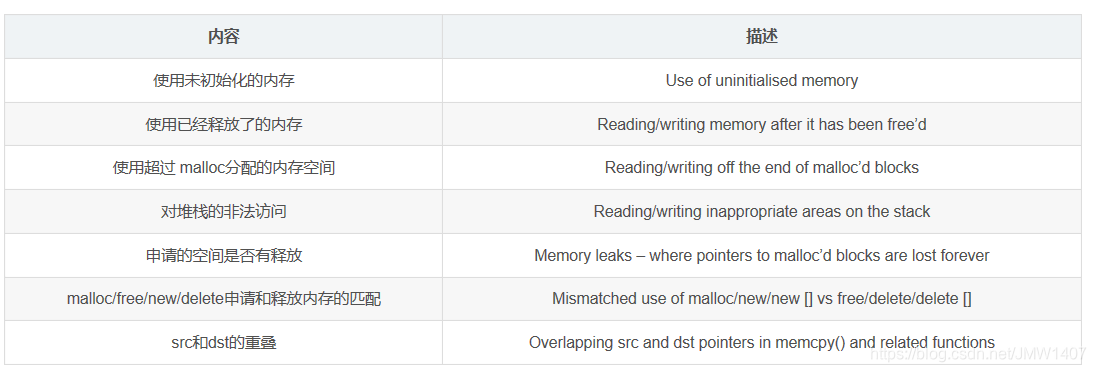
最常用的工具,用来检测程序中出现的内存问题,所有对内存的读写都会被检测到,一切对malloc()/free()/new/delete的调用都会被捕获。所以,Memcheck 工具主要检查下面的程序错误- 能够检测:
- 使用未初始化的内存 (Use of uninitialised memory)
- 使用已经释放了的内存 (Reading/writing memory after it has been free’d)
- 使用超过 malloc分配的内存空间(Reading/writing off the end of malloc’d blocks)
- 对堆栈的非法访问 (Reading/writing inappropriate areas on the stack)
- 申请的空间是否有释放 (Memory leaks – where pointers to malloc’d blocks are lost forever)
- malloc/free/new/delete申请和释放内存的匹配(Mismatched use of malloc/new/new [] vs free/delete/delete [])
- src和dst的重叠(Overlapping src and dst pointers in memcpy() and related functions)
- 重复free
Callgrind
和gprof类似的分析工具,但它对程序的运行观察更是入微,能给我们提供更多的信息。和gprof不同,它不需要在编译源代码时附加特殊选项,但加上调试选项是推荐的。Callgrind收集程序运行时的一些数据,建立函数调用关系图,还可以有选择地进行cache模拟。在运行结束时,它会把分析数据写入一个文件。callgrind_annotate可以把这个文件的内容转化成可读的形式。Cachegrind
Cache分析器,它模拟CPU中的一级缓存I1,Dl和二级缓存,能够精确地指出程序中cache的丢失和命中。如果需要,它还能够为我们提供cache丢失次数,内存引用次数,以及每行代码,每个函数,每个模块,整个程序产生的指令数。这对优化程序有很大的帮助。Helgrind
它主要用来检查多线程程序中出现的竞争问题。Helgrind寻找内存中被多个线程访问,而又没有一贯加锁的区域,这些区域往往是线程之间失去同步的地方,而且会导致难以发掘的错误。Helgrind实现了名为“Eraser”的竞争检测算法,并做了进一步改进,减少了报告错误的次数。不过,Helgrind仍然处于实验阶段。Massif
堆栈分析器,它能测量程序在堆栈中使用了多少内存,告诉我们堆块,堆管理块和栈的大小。Massif能帮助我们减少内存的使用,在带有虚拟内存的现代系统中,它还能够加速我们程序的运行,减少程序停留在交换区中的几率。1.3、使用原理
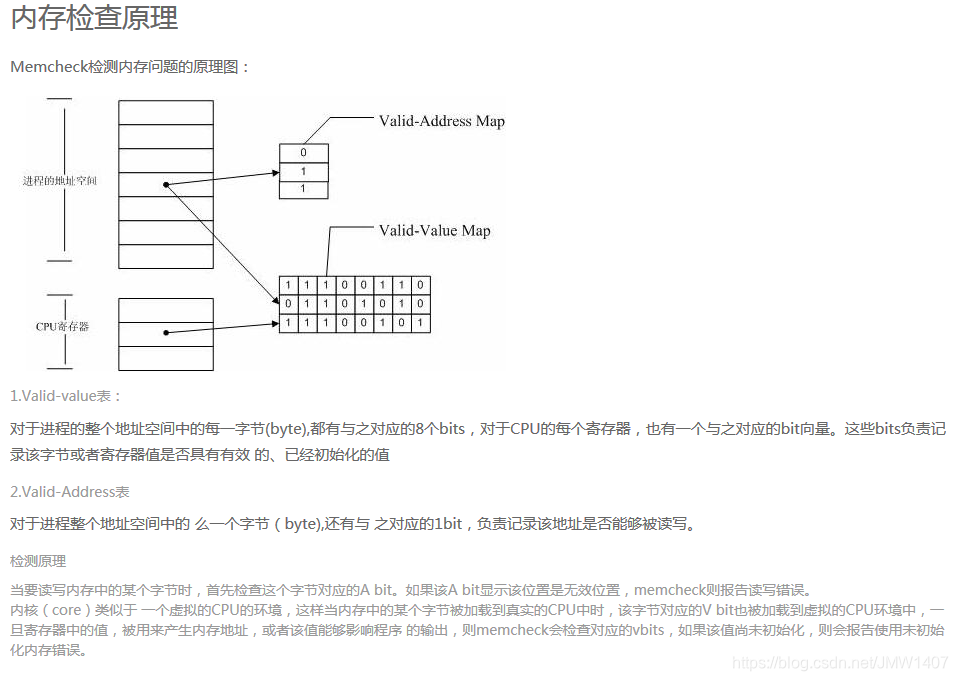 Memcheck 能够检测出内存问题,关键在于其建立了两个全局表。
Memcheck 能够检测出内存问题,关键在于其建立了两个全局表。 1、Valid-Value 表:
对于进程的整个地址空间中的每一个字节(byte),都有与之对应的 8 个 bits;对于 CPU 的每个寄存器,也有一个与之对应的 bit 向量。这些 bits 负责记录该字节或者寄存器值是否具有有效的、已初始化的值。2、Valid-Address 表
对于进程整个地址空间中的每一个字节(byte),还有与之对应的 1 个 bit,负责记录该地址是否能够被读写。检测原理:
- 当要读写内存中某个字节时,首先检查这个字节对应的 A bit。如果该A bit显示该位置是无效位置,memcheck 则报告读写错误。
- 内核(core)类似于一个虚拟的 CPU 环境,这样当内存中的某个字节被加载到真实的 CPU 中时,该字节对应的 V bit也被加载到虚拟的 CPU 环境中。一旦寄存器中的值,被用来产生内存地址,或者该值能够影响程序输出,则 memcheck 会检查对应的V bits,如果该值尚未初始化,则会报告使用未初始化内存错误。
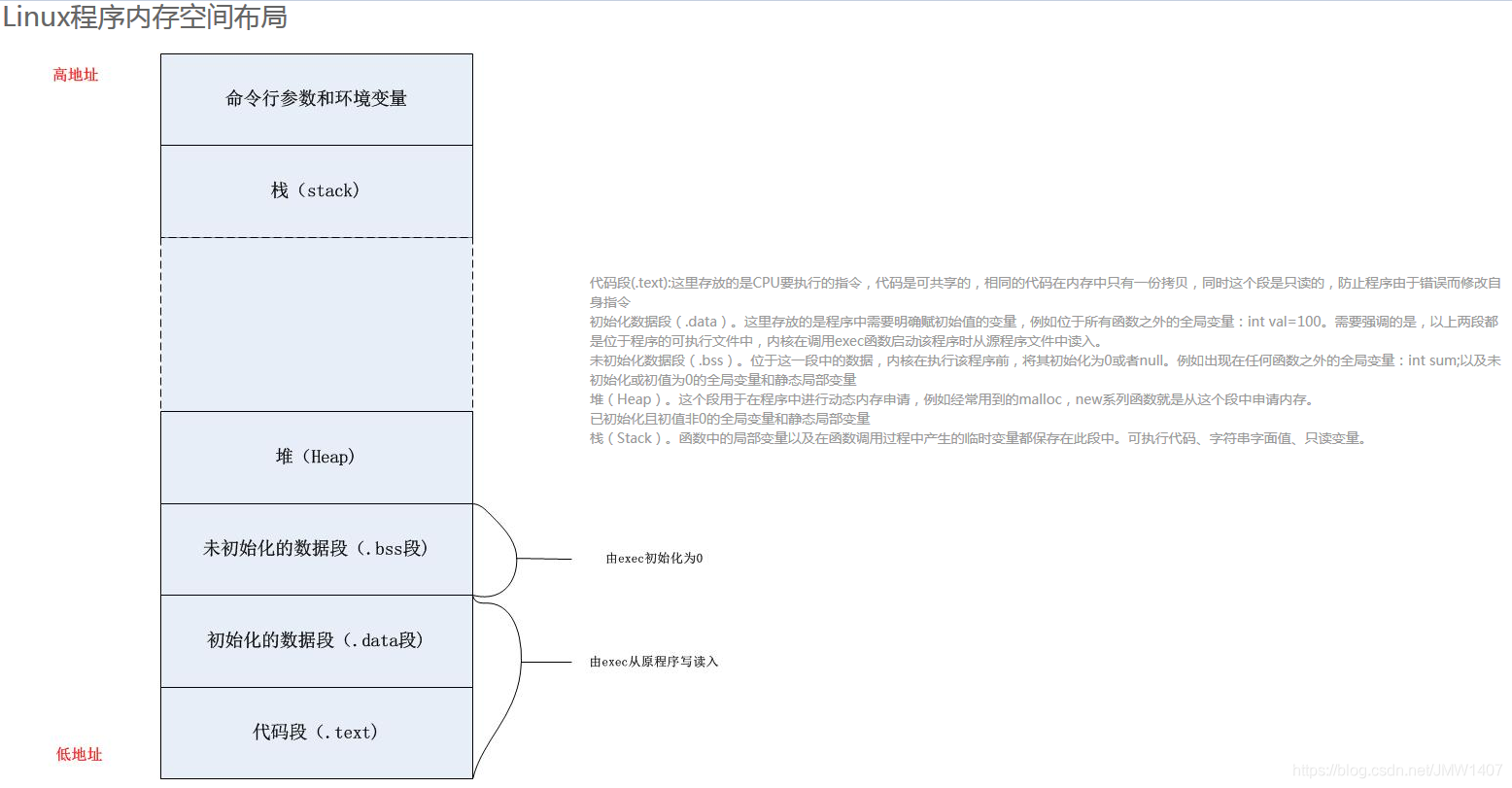
1.4、具体使用
1. 使用未初始化的内存(使用野指针) 这里我们定义了一个指针p,但并未给他开辟空间,即他是一个野指针,但我们却使用它了 Valgrind检测出我们程序使用了未初始化的变量,但并未检测出内存泄漏。
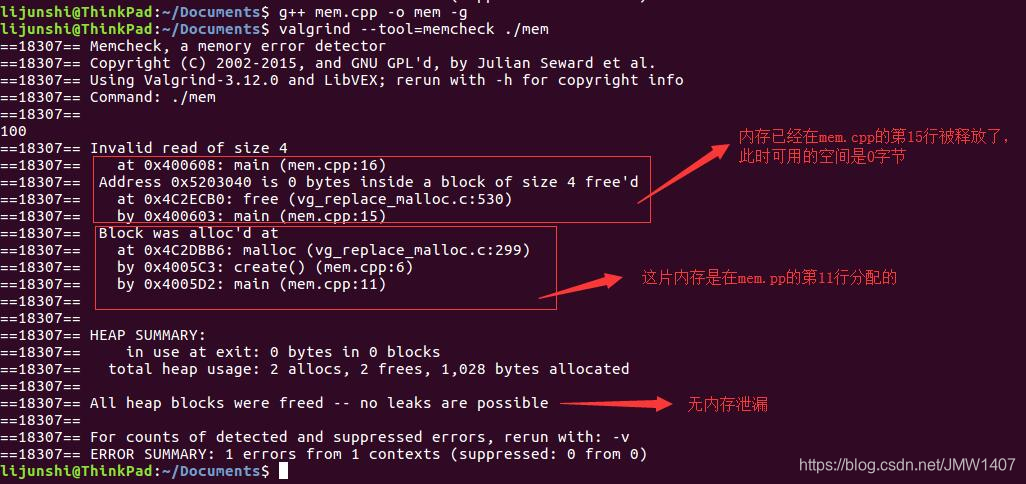
Valgrind检测出我们程序使用了未初始化的变量,但并未检测出内存泄漏。  2.在内存被释放后进行读/写(使用野指针) p所指向的内存被释放了,p变成了野指针,但是我们却继续使用这片内存。
2.在内存被释放后进行读/写(使用野指针) p所指向的内存被释放了,p变成了野指针,但是我们却继续使用这片内存。 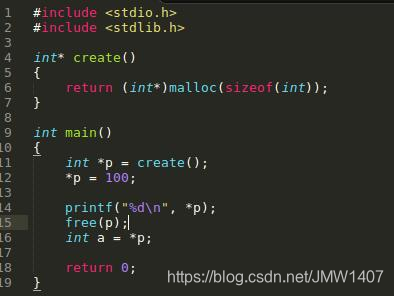
 3.从已分配内存块的尾部进行读/写(动态内存越界) 我们动态地分配了一段数组,但我们在访问个数组时发生了越界读写,程序crash掉。
3.从已分配内存块的尾部进行读/写(动态内存越界) 我们动态地分配了一段数组,但我们在访问个数组时发生了越界读写,程序crash掉。  Valgrind检测出越界的位置。
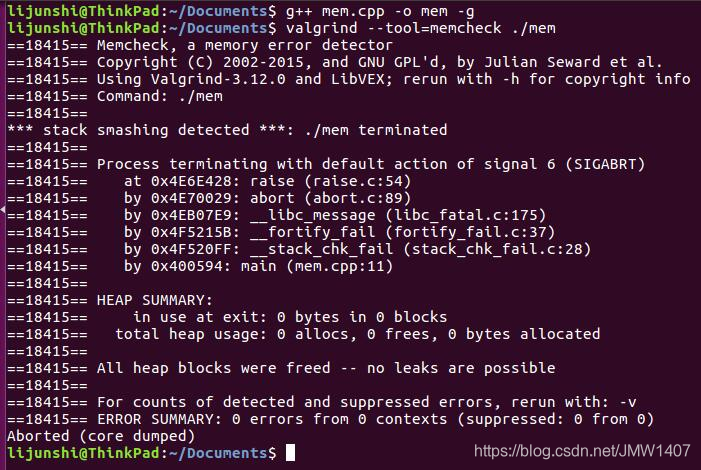
Valgrind检测出越界的位置。 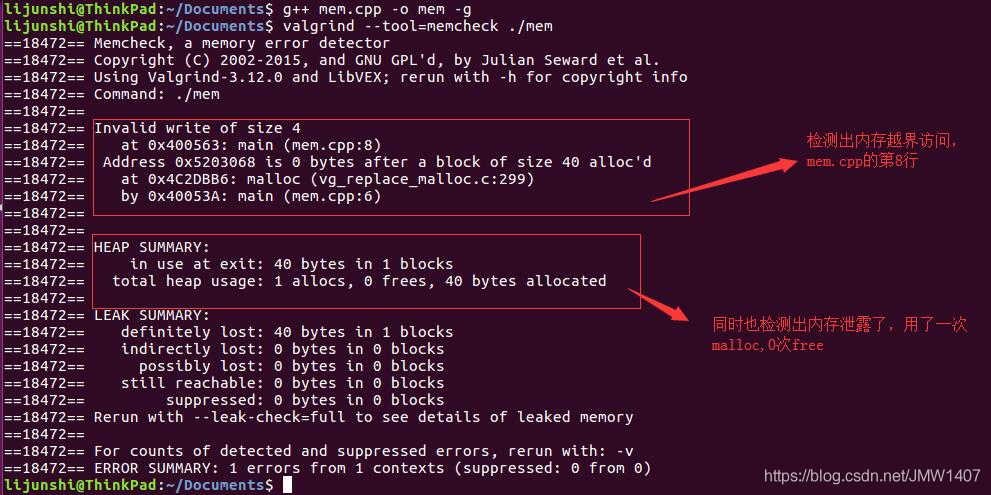 注意:Valgrind不检查静态分配数组的使用情况!所以对静态分配的数组,Valgrind表示无能为力!比如下面的例子,程序crash掉,我们却不知道为什么。
注意:Valgrind不检查静态分配数组的使用情况!所以对静态分配的数组,Valgrind表示无能为力!比如下面的例子,程序crash掉,我们却不知道为什么。 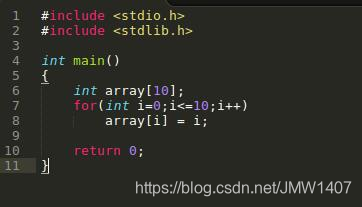
 4.内存泄漏 内存泄漏的原因在于没有成对地使用malloc/free和new/delete,比如下面的例子。
4.内存泄漏 内存泄漏的原因在于没有成对地使用malloc/free和new/delete,比如下面的例子。 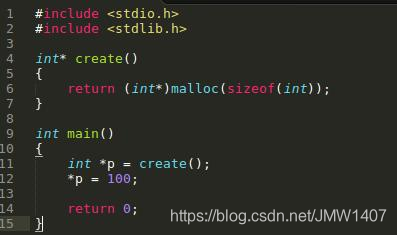 Valgrind会给出程序中malloc和free的出现次数以判断是否发生内存泄漏,比如对上面的程序运行memcheck,Valgrind的记录显示上面的程序用了1次malloc,却调用了0次free,明显发生了内存泄漏!
Valgrind会给出程序中malloc和free的出现次数以判断是否发生内存泄漏,比如对上面的程序运行memcheck,Valgrind的记录显示上面的程序用了1次malloc,却调用了0次free,明显发生了内存泄漏! 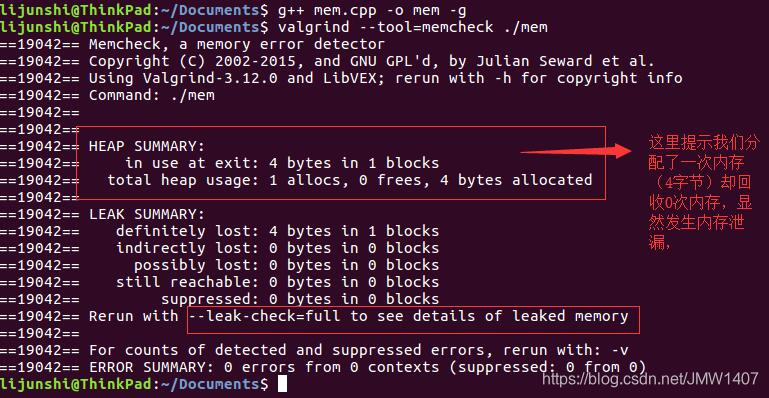
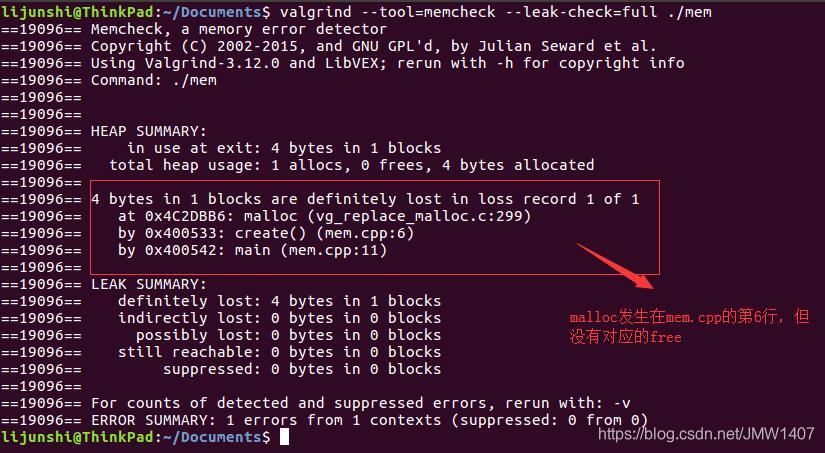
正常使用new/delete和malloc/free是这样子的:
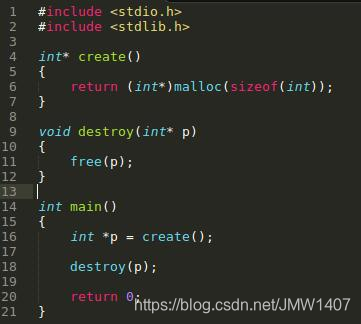
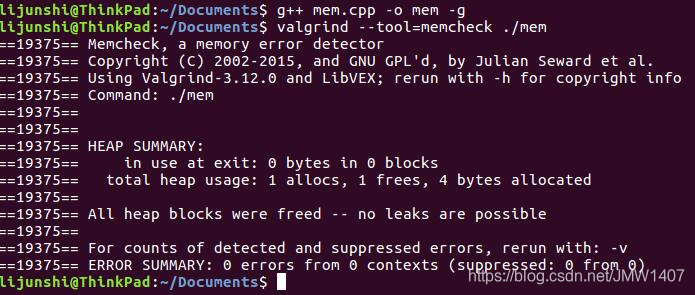 而不匹配地使用malloc/new/new[] 和 free/delete/delete[]则会被提示mismacth:
而不匹配地使用malloc/new/new[] 和 free/delete/delete[]则会被提示mismacth: 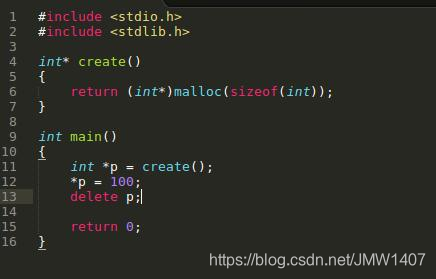
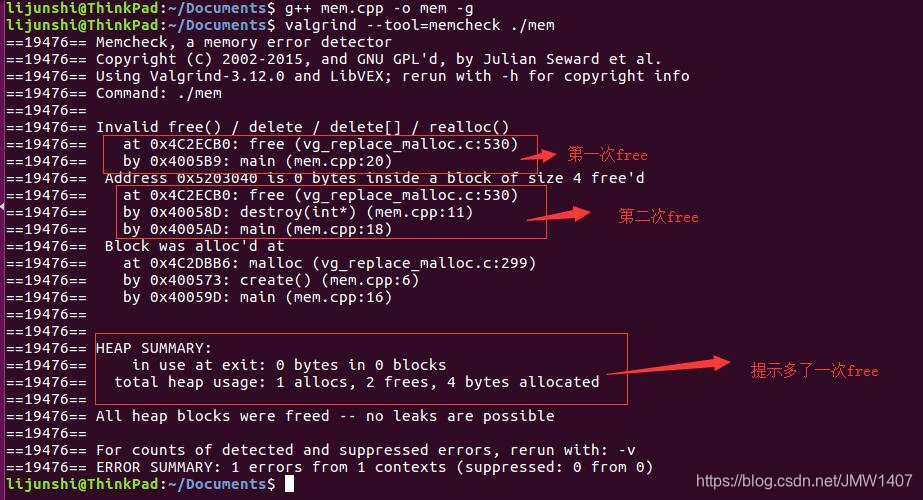
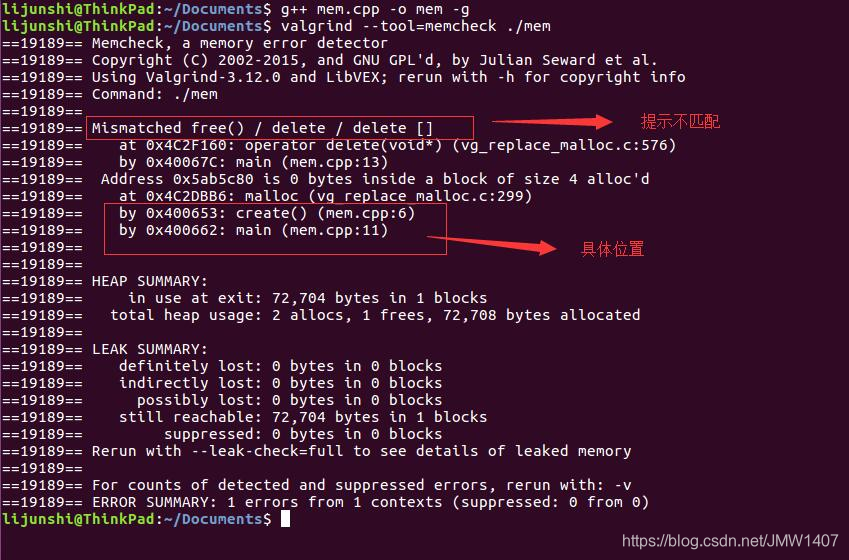 6.两次释放内存 double free的情况同样是根据malloc/free的匹配对数来体现的,比如free多了一次,Valgrind也会提示。
6.两次释放内存 double free的情况同样是根据malloc/free的匹配对数来体现的,比如free多了一次,Valgrind也会提示。 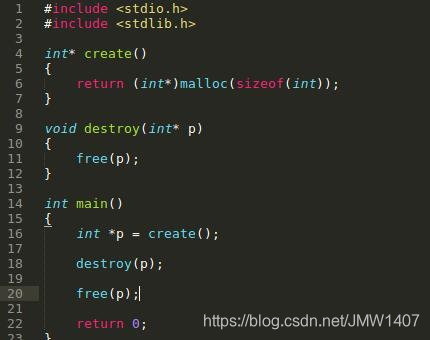
参考
1、https://www.cnblogs.com/guochaoxxl/p/6970090.html
2、https://www.cnblogs.com/skyfsm/p/8823170.html 3、https://blog.csdn.net/gatieme/article/details/51959654 4、https://blog.csdn.net/andylauren/article/details/93189740 5、https://www.cnblogs.com/AndyStudy/p/6409287.html
你可能感兴趣的文章